Table des matières
TD Communication dans les systèmes informatiques: Communications séries asynchrones – UART Arduino
1. Etude d’une trame en communication série asynchrone
Question 1.1
Quel est le rôle du bit de parité dans une trame série asynchrone ?
Question 1.2
En considérant une communication 9600bds, 8 bits de données, pas de parité, 1 bit de stop, quelle est la durée du bit de stop ? Quel est l'impact du nombre de bits de stop sur la communication ?
Question 1.3
A débit fixé (par exemple 9600 bds) comment rendre la communication plus rapide ?
Question 1.4
Dans une transmission asynchrone à 9600 bds 8N1, quelle est la durée nécessaire à l’émission d’un caractère?
Question 1.5
Représentez le chronogramme de la transmission (sans attente) de 0x02A01358 en msB first (au format décrit en 1.2).
Solutions partie 1:
Question 1.1
Le bit de parité permet d’ajouter un mécanisme de détection d’erreur via de la redondance dans la trame. C’est à dire qu’en ajoutant à la trame un bit dont la valeur est calculée par l’émetteur de la trame, le récepteur de la trame peut effectuer le même calcul et doit trouver le même résultat, sinon cela signifie qu’une erreur s’est produit. Attention, par contre, ce n’est pas parce que le récepteur trouve le même résultat qu’il n’y a pas d’erreur dans la trame.
Supposons que l’émetteur et le récepteur utilisent la convention « parité paire ». L’émetteur envoie au format 8E1 la donnée de valeur 0x84. (Faîtes la conversion vers binaire pour voir que 2 bits de la données sont à 1). En convention « parité paire », l’émetteur attachera un bit de parité de valeur 0 pour avoir un nombre pair de bits à 1 dans « la donnée + la parité ».
Supposons 3 cas :
- La trame est transmise sans erreur : le récepteur reçoit une la trame contenant la donnée à 0x84 et un bit de parité à 0. Etant configuré en convention « parité paire », il va considérer cette trame comme correcte car elle contient bien un nombre pair de bits à 1 dans « la donnée + la parité ».
- La trame est transmise avec une erreur (soit sur les bits de données, soit sur le bit de parité). Cela signifie qu’un des bits est erroné, donc sa valeur passe de 0 à 1 ou de 1 à 0 . Le récepteur étant configuré en convention « parité paire », il va considérer cette trame comme incorrecte car elle contient alors un nombre impair de bits à 1 dans « la donnée + la parité ».
- La trame est transmise avec deux erreurs (soit sur les bits de données, soit sur le bit de parité). Cela signifie que deux des bits sont erronés, donc leurs valeurs passe de 0 à 1 ou de 1 à 0 mais si l’on compte le nombre de bits à 1 dans la trame, sa parité n’est pas changée. Le récepteur étant configuré en convention « parité paire », il va considérer cette trame comme correcte car elle contient alors un nombre pair de bits à 1 dans « la donnée + la parité ». L’erreur n’est donc pas détectée.
En généralisant, on peut déterminer que le contrôle de parité permet de détecter un nombre impair d’erreurs dans la trame. Supposons un taux d’erreur bit de 1/10000. Cela signifie qu’en moyenne, un bit transmis voit sa valeur changée tout les 10000 bits. De manière simplificatrice (en réalité cela est plus complexe car il faudrait connaître la distribution temporelle des erreurs), nous pouvons considérer dans une trame au format 8E1 (contenant donc 1bit de start + 8bits de données + 1 bit de parité + 1 bit de stop, soit 11bits) sera de l’ordre du 1/1000. Avec ces hypothèse, la probabilité d’avoir 2 bits erronés dans la même trame est bien plus réduite, et l’on peut dire (à la louche) que le contrôle de parité permet de détecter la majorité des erreurs.
Question 1.2
En communication série asynchrone, tous les bits ont la même durée par définition. Le bit de stop y compris. En considérant un débit de 9600 Bauds, les bits ont une durée de 1/9600 seconde soit à peu près 104us. Dans d’autres formats de trame, il est possible d’avoir 2 bits de stop ou même 1.5 bit de stop. Cela signifie que la durée de maintient à l’état logique 1serait respectivement de 2*104us ou 1.5*104us. Cela permet de retarder le moment où un prochain bit de start pourrait arriver, afin par exemple de garantir que le récepteur de la trame aura eu le temps de traiter la trame reçue avant d’en recevoir une nouvelle. On dit que l’on réduit de débit utile en ajoutant des bits de stop (voir slide 60 du cours). A baudrate fixé, cela conduit à réduire le nombre de bits de données utiles échangés par unité de temps et donc à ralentir la communication.
Question 1.3
Nous venons de voir à la question 1.2 que réduire le débit utile ralentit la communication. L’inverse est vrai également. Donc que pouvons nous faire pour augmenter le débit utile :
- Réduire le nombre de bits de stop de la trame, mais il en faut au minimum 1 pour permettre le front entre le bit de stop et le bit de start suivant qui permet au récepteur de se resynchroniser sur le début de la nouvelle trame.
- Désactiver le contrôle de parité.
- Augmenter le nombre de bits de données dans la trame (varie généralement entre 5 et 12 maximum). Les raisons pour laquelle il n’est pas souhaitable d’augmenter trop fortement le nombre de bits de données sont multiples et deux sont données en annexe 1.
- Il existe une autre approche pour accélérer la communication mais elle ne s’applique pas au niveau de la trame. Elle consiste à compresser le message (composé de plusieurs octets, donc une unité de donnée plus grosse que l’octet) pour en réduire la taille. Pour cela, différentes méthodes existent, avec ou sans perte d’information. Parmi les méthodes sans pertes, le codage d’Huffman permet par exemple de coder les symboles avec des séquences de bits d’autant plus courtes que le symbole apparaît souvent dans le message, afin de réduire en moyenne le nombre de bits utilisés pour coder les différents symboles du message.
Annexe 1:
- A taux d’erreur bit donné, la probabilité qu’une trame contienne au moins un bit erroné croit avec la taille de la trame. Faire une trame de par exemple 10000bits avec un taux d’erreur bit de 1/10000 conduit à ce qu’une grande partie des trames contiennent des erreurs, ce qui conduit à jeter complètement les trames en question. Alors que pour les mêmes 10000bits rangés dans des trames de 10 bits, seulement quelques trames seraient erronées.
- En communication série asynchrone, l’émetteur et le récepteur n’ont pas d’horloge commune échangée sur le bus. Cela signifie qu’ils ont chacun leur propre horloge et qu’elles ne sont pas exactement synchronisées entre elles. Soit tbit=1/Baudrate, chacun des hôtes utilise en réalité une base de temps légèrement différente : l’émetteur utilise tbit_e=tbit+epsilon_e et le récepteur utilise tbit_r=tbit+epsilon_r. A chaque bit, l’horloge du récepteur se décale par rapport à celle de l’émetteur de tbit_e-tbit_r=Delta_tbit. Le front apparaissant au début du bit de start permet à l’émetteur de fournir un signal TOP-DEPART au récepteur mais à partir de cet instant, les horloges se décalent… Pour déterminer la valeur du premier bit de donnée, le récepteur devrait échantillonner le signal 1.5 tbit après le front du start, mais il ne le fait pas exactement à cette instant, mais avec une erreur de 1.5 Delta_tbit. Une erreur Delta_tbit s’ajoute pour chaque bit de donnée de la trame. A force de cumuler ces erreurs, le récepteur risque d’échantillonner le signal hors de l’intervalle de temps correspondant au bit souhaité (soit au niveau des transitoires, quand la tension change, soit carrément au niveau d’un autre bit). Cela se produit lorsque Delta_tbit multiplié par le nombre de bit de données de la trame se rapproche de t_bit/2. Supposons que les erreurs relatives de tbit au niveau de l’émetteur et du récepteur soit de l’odre de 2 %, dans le pire cas il y aura donc de l’ordre de 4 % d’erreur entre tbit_e et tbit_r. Dans cette situation, le treizième bit est échantillonné par le récepteur avec une erreur de 52 % tbit, ce qui revient à lire la valeur du bit suivant ou précédent…. Pour éviter ce problème, il est nécessaire de resynchroniser régulièrement l’émetteur et le récepteur en démarrant une nouvelle trame.
Question 1.4
La trame au format 8N1 comporte 10bits (1 start + 8 données + 1 stop) pour envoyer la donnée 8 bits d’un caractère . Chacun des bits de la trame est envoyé sur le canal pendant 1/9600 seconde. Il faut donc 10/9600 seconde pour envoyer la trame soit 1,04ms . Ceci est la durée pendant laquelle le canal de communication est occupé par l’envoi de la trame et correspond à une cadence d’envoi maximale de 960 caractères par seconde. En raison des latences notamment dues à la sérialisation et à la désérialisation de la trame, ainsi qu’au temps de trajets sur le canal, la latence (durée entre le début de l’envoi du message et la fin de la réception) est néanmoins supérieure à 1,04ms.
Question 1.5
Les données sont émises au format 8N1, donc 1 octet à la fois. MsB first signifie que c’est l’octet (Byte) de poids fort qui est émis en premier ; les octets vont donc être émis dans cet ordre:0x02 puis 0xA0, puis 0x13 puis 0x58. Chacun de ces octets va être émis grâce à une trame asynchrone, en lsb first (bit de poids faible d’abord). Nous allons supposer qu’il n’y a pas d’attente entre l’envoi des différents octets. Il faut commencer par traduire en binaire les octets sur 8bits : le premier, 0x02= 00000010b Attention à ne pas faire une erreur que je vois souvent chez les étudiants (sans raison valable): ne pas inverser les quartets (paquets de 4 bits), ici en envoyant le 2 puis le 0 par exemple… Le quartet n’est pas une unité de donnée utile ici, seuls sont spécifiés l’ordre des octets et des bits. Ici la donnée est envoyée bit de poids faible d’abord donc bit 0 puis bit 1, etc jusqu’à bit 7. La valeur 0x02 est donc émise sous la forme 01000000.
Une fois la donnée convertie et bien ordonnée, il faut éventuellement lui attacher un bit de parité (ce n’est pas le cas ici car format de trame 8N1) puis l’encadrer avec le bit de start (0 notée S car start commence par S) au début et le bit de stop (1 notée P car stop finit par P) à la fin pour former la trame. La trame codant la valeur 2 est donc émise sous la forme S01000000P.
La question est de tracer le chronogramme, il faut donc faire apparaître le temps sur l’axe horizontal. Ici, il faut que chaque bit dure 104us (1/9600 s). On simplifie le tracé en choisissant 1 carreau =tbit. Pour l’axe vertical, il faut savoir à quel standard on trace le chronogramme, Ici, ce n’est pas spécifié dans la question donc on peut tracer le chronogramme LOGIQUE, c’est à dire faisant apparaître les niveaux 0 (bas) et 1 (haut). On aurait également pu demander explicitement le tracé par exemple au standard électrique TTL auquel cas il aurait fallu utiliser 0V (bas) et 5V (haut). Si le tracé avait été demandé au standard RS232, il aurait fallu utiliser +3à+25V (bas) et -3à-25V (haut).
Le tracé continue avec l’envoi des octets suivants :
0xA0= 10100000b 0x13= 00010011b 0x58=01011000b

2. Gestion d’un buffer circulaire
Dans les communications entre systèmes informatiques, on utilise une mémoire tampon pour le stockage des caractères reçus ou en attente d’émission. Cette mémoire tampon permet :
- de limiter l’utilisation des signaux de protocole pour le contrôle de flux,
- de construire facilement le programme par couches (par ex. une couche de réception, et une couche d’utilisation, cf. réseaux).
Cette démarche est très adaptée à une gestion par interruption.
Nous proposons dans cet exercice de gérer la mémoire de façon circulaire. Cette gestion se fait aussi bien pour le « remplissage » du tampon que pour le « vidage ».
- Remplissage du tampon : les données reçues sont écrites dans le tampon tant qu’il y a de la place ; si la fin du tampon est atteinte, on recommence à écrire dès le début.
- Vidage du tampon : on ne peut venir lire dans le tampon uniquement si des données sont disponibles.
Le tampon circulaire est caractérisé par :
- un indice de lecture : read_index,
- un indice d'écriture : write_index,
- une variable définissant le nombre de données présentes dans le tampon : nb_token_available
- une variable indiquant la nombre maximum de données stockables dans le tampon: buffer_size
Dans tout l’exercice nous utiliserons la structure suivante :
- structfifo.cpp
struct charFifo{ char * buffer ; //la zone mémoire contenant les données du buffer, chaque donnée est un char dans cet exemple unsigned int buffer_size; //une variable définissant la taille du buffer unsigned int write_index ; //l'index d'écriture dans le tableau de données unsigned int read_index ; //l'index de lecture dans le tableau de données unsigned int nb_token_available ; //le nombre de données disponibles dans le buffer };
Une variable de type struct charFifo doit être définie pour chaque Fifo manipulée par le programme, par exemple:
- structfifo1.cpp
struct charFifo fifo1;
Attention, cette structure ne définit pas le tableau servant à stocker les données dans la fifo mais uniquement la structure permettant de les manipuler. Un tableau de taille FIFOSIZE1 caractères doit être réservé de la manière suivante:
- structfifo2.cpp
#define FIFOSIZE1 3 char fifoBuffer1[FIFOSIZE1];
Question 2.0
Revoir l'explication des slides 43 et 44 sur la vidéo https://youtu.be/-El8ZcLixFU?t=2123 et déterminer ce qui change entre l'exemple du cours et cet exercice de TD. Essayer de trouver un intérêt à l'approche du TD par rapport à celle du cours.
Question 2.1
Donner l’algorithme de la procédure d'initialisation du remplissage circulaire : void fifo_init(struct charFifo * ptr_fif, char * ptr_buf, const unsigned int buf_size) .
En entrée :
- struct charFifo * ptr_fif : pointeur sur la structure de file utilisée
- char * ptr_buf : adresse de départ du tableau destiné à stocker les données de la fifo
- const unsigned int buf_size : taille de la fifo
REMARQUE IMPORTANTE: ptr_fif est un pointeur passé en paramètre à la fonction. La fonction peut donc accéder à la zone mémoire pointée par ptr_fif pour en lire ou en modifier le contenu. La zone pointée par ptr_fif est donc en entrée/sortie pour la fonction.
Ici le type de ce pointeur est struct charFifo * . La zone mémoire indiquée par ptr_fif contient donc (au moins) une variable de type structure charFifo. Grâce à cet unique paramètre, il est donc possible de passer à la fonction un ensembles de données associée à une même variable charFifo, et accessible en entrée/sortie. Cette approche est un premier pas vers l'approche de programmation appelée “Orientée Objet” qui vous sera présentée bientôt. Dans le corps de la fonctions, il faudra utiliser 2 opérateurs que vous connaissez pour accéder aux champs de la variable structure:
- L'opérateur * pour accéder à la variable pointée par le pointeur
- L'opérateur . pour accéder à chacun des champs de la sturcture
par exemple pour accéder au champ read_index, il faudra faire: (*ptr_fif).read_index
Ceci peut également être fait à l'aide d'un seul opérateur → qui remplit le rôle des 2 opérateurs * et . La ligne précédente peut donc s'écrire ptr_fif→read_index
Pour l'appel de la fonction, il faudra veiller à fournir une valeur effective de paramètre du bon type, donc un pointeur vers une variable charFifo. Pour cela, il faut utiliser l'opérateur & qui permet d'obtenir l'adresse d'une variable.
Question 2.2
Dessiner l’espace mémoire occupé par fifoBuffer1 si le tableau commence à l’adresse 4 et l’état des différents champs de la structure fifo1 après appel de : fifo_init(& fifo1, fifoBuffer1, FIFOSIZE1);
Question 2.3
Donner l’algorithme de la procédure de remplissage circulaire : char fifo_write(struct charFifo * ptr_fif, const char token) permettant de stocker une donnée dans le buffer circulaire. On admettra que si le tampon est plein, les données supplémentaires ne sont pas stockées et la fonction est non bloquante.
En entrée :
- struct charFifo * ptr_fif: pointeur sur la structure de file utilisée
- const char token : valeur à écrire dans la file
En sortie :
- un caractère = 0 : valeur NON écrite dans la file, = 1 : valeur écrite dans la file
Question 2.4
Donner l’algorithme de la procédure de vidage circulaire : char fifo_read(struct charFifo * ptr_fif, char * ptr_token) permettant de lire une donnée dans le buffer circulaire. La fonction est non bloquante.
En entrée :
- struct charFifo * ptr_fif: pointeur sur la structure de file utilisée
- char * ptr_token : pointeur vers la variable dans laquelle ranger la donnée lue depuis la file.
En sortie :
- un caractère = 0 : valeur NON lue depuis la file (aucun caractère n’est disponible), = 1 : valeur lue depuis la file via le paramètre *ptr_c.
Question 2.5
En considérant la variable fifo1 telle qu’initialisée à l’exercice 2.2, compléter les colonnes du tableau après l’exécution de chaque appel de fonction :
Solutions partie 2:
Question 2.0
Par rapport à l'exemple du cours, la structure de donnée et les fonctions du TD permettent d'utiliser différents tableaux de différentes tailles pour différentes FIFOs, alors que l'exemple du cours utilisait une taille fixe FIFOSIZE, commune à toutes les FIFOs. Dans le TD, on peut par exemple utiliser:
- structfifo4.cpp
#define FIFOSIZE2 24 char fifoBuffer2[FIFOSIZE2];
et appeler la fonction d'initialisation de la fifoBuffer2 avec la taille FIFOSIZE2.
Comme la taille des différents tableaux associés aux FIFOs peut varier, dans la structure ce sont l'adresse de début de tableau et la taille du tableau qui sont stockées pour CHAQUE FIFO.
Question 2.1
- fifocode1.cpp
void fifo_init(struct charFifo * ptr_fif, char * ptr_buf, const unsigned int buf_size) { ptr_fif->fifo_size=f_size; //la taille du buffer de cette FIFO est stockée dans la structure ptr_fif->nb_available=0; //initialement la FIFO est vide, il y a donc 0 jetons disponibles ptr_fif->write_index=0; //on commence arbitrairement l'écriture ET la lecture à la case 0 ptr_fif->read_index=0; ptr_fif->data=buf; //le pointeur de donnée de la FIFO pointe sur la zone mémoire du tableau passé en paramètre }
Question 2.2
fifoBuffer1 est un tableau de 3 octets. Il occupe les adresses en mémoire de la zone 4 à 6 car la première case du tableau fifoBuffer1 est en 4 et qu'il fait 3 cases de long.
Quelque part dans la mémoire, au choix du compilateur, la variable structure fifo1 associée au tableau fifoBuffer1 prend de la place. Les différents champs de la structure sont stockés à la suite avec éventuellement des vides entre les champs à cause de contraintes d’alignement. La taille occupée en mémoire par les différents champs dépend du compilateur et de l’architecture matérielle de la cible.
Il est néanmoins possible de déterminer le contenu des champs de la variable fifo1 après initialisation:
- fifocode2.cpp
buffer =4; buffer_size=3; write_index=0; read_index=0; nb_token_available=0;
Question 2.3
- fifocode4.cpp
char fifo_write(struct charFifo * ptr_fif, const char token){ if(ptr_fif->nb_token_available >= ptr_fif->buffer_size) return 0 ; //FIFO PLEINE ptr_fif->data[ptr_fif->write_index] = token ; //la donnée est écrite dans le buffer à la case write_index (ptr_fif->write_index)++; //write_index est incrémenté if( ptr_fif->write_index >= ptr_fif->buffer_size) //si il dépasse la taille du buffer, il est remis à 0, cela remplace l'opérateur modulo ptr_fif->write_index = 0 ; ptr_fif->nb_token_available++; //il y a une donnée de plus disponible dans la FIFO return 1; //OK }
Question 2.4
- fifocode4.cpp
char fifo_read(struct charFifo * ptr_fif, char * ptr_token){ if( ptr_fif->nb_token_available == 0) return 0; //FIFO VIDE *ptr_token=ptr_fif->data[ptr_fif->read_index]; //la donnée est lue depuis le buffer à la case read_index (ptr_fif->read_index )++; //read_index est incrémenté if( ptr_fif->read_index >= ptr_fif->buffer_size) //si il dépasse la taille du buffer, il est remis à 0, cela remplace l'opérateur modulo ptr_fif->read_index = 0 ; ptr_fif->nb_token_available--; //il y a une donnée de moins disponible dans la FIFO return 1; //OK }
Question 2.5
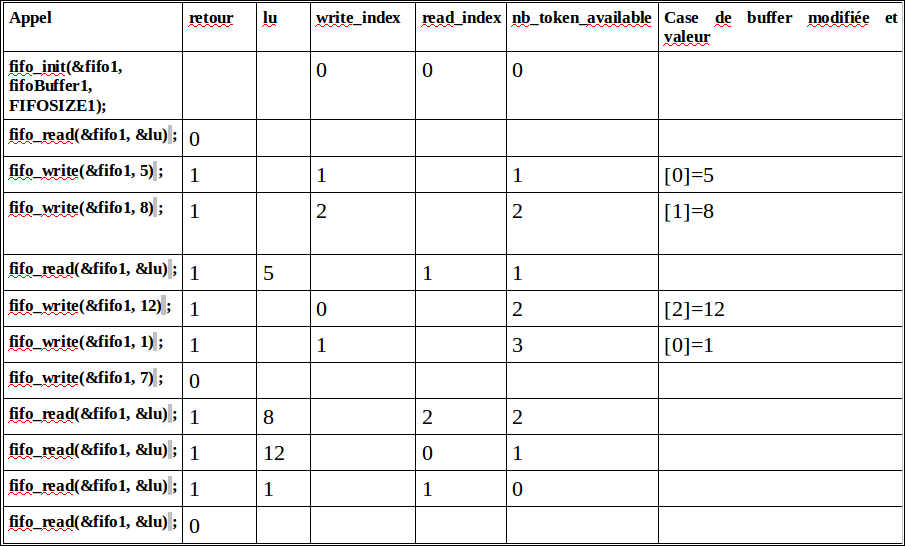
 Visionner les détails de la correction en vidéo:
Visionner les détails de la correction en vidéo:
En déduire la séquence de jetons qui ont pu être écrits dans la FIFO et vérifier que la même séquence a pu être lue depuis la FIFO (hormi la donnée perdue lorsque la FIFO était pleine).
3 : Utilisation de la FIFO (buffer circulaire) dans une application
On considère une communication série 9600 bauds, 8 bits, 1 stop, pas de parité entre un ordinateur et une imprimante disposant d’une FIFO (tampon circulaire) de 256 octets. La vitesse d’impression est de 5 ms pour un caractère (la vitesse d’impression correspond à la vitesse de vidage du buffer).
Question 3.1
En admettant que la taille du buffer circulaire de l'imprimante est de 256 octets, au bout de combien de temps le buffer sera-t-il plein si l'imprimante reçoit les caractères à vitesse maximale (sans pause entre les caractères)?
Question 3.2
Même question si il y a 2 ms d'attente entre l'envoi de chaque caractère.
Question 3.3
On cherche à imprimer une page d'un maximum de 3500 caractères sans provoquer de débordement du buffer circulaire. Calculer la taille minimum nécessaire du buffer circulaire si l'imprimante reçoit les caractères à vitesse maximale (sans pause entre les caractères)?
Solutions partie 3:
Question 3.1
La première chose à faire est d’exprimer les vitesses de remplissage et de vidage de la FIFO sous les mêmes unités:
- Elle se remplie à 9600Bauds en 8N1sans pauses soit: 960 caractères par seconde.
- Elle se vide à la vitesse d’impression: 5ms par caractère, soit 1/0.005=200 caractères par seconde.
Donc on voit que la FIFO se remplit plus rapidement qu’elle ne se vide, elle va donc forcément déborder à un moment donné:
soit  le nombre de caractères dans la FIFO,
le nombre de caractères dans la FIFO,  la vitesse de remplissage,
la vitesse de remplissage,  la vitesse de vidage et
la vitesse de vidage et  le temps commençant au début du remplissage:
Tant que la FIFO n’a pas débordé, nous avons :
le temps commençant au début du remplissage:
Tant que la FIFO n’a pas débordé, nous avons :

La FIFO devient pleine lorsque  , déterminons la date correspondante
, déterminons la date correspondante 
 donc
donc 
Application Numérique:  donc la fifo est pleine au bout de 337ms après le début du remplissage. Il faut alors arrêter de lui envoyer des caractères pour qu’elle imprime le contenu de la FIFO.
donc la fifo est pleine au bout de 337ms après le début du remplissage. Il faut alors arrêter de lui envoyer des caractères pour qu’elle imprime le contenu de la FIFO.
Question 3.2
Ajouter une pause de 2ms entre l'envoi de chaque caractère à l'imprimante revient à réduire la cadence de remplissage de la FIFO. Calculons la durée pour l'envoi de chaque caractère  et la nouvelle vitesse de remplissage
et la nouvelle vitesse de remplissage  :
:
= durée de l'envoi d'un caractère + durée de la pause
Application Numérique:
 s et
s et  caractères par seconde.
caractères par seconde.
On peut reprendre le calcul de l'exercice précédent en utilisant :
La FIFO devient pleine lorsque , déterminons la date correspondante 
 donc
donc 
Application Numérique:  donc la fifo est pleine au bout de 1998ms après le début du remplissage. Il faut alors arrêter de lui envoyer des caractères pour qu’elle imprime le contenu de la FIFO. Ajouter la pause entre l'envoi des caractère permet à la FIO d'être pleine moins souvent et donc permet de moins souvent solliciter le PC pour qu'il arrête ou reprenne l'envoi des données vers l'imprimante.
donc la fifo est pleine au bout de 1998ms après le début du remplissage. Il faut alors arrêter de lui envoyer des caractères pour qu’elle imprime le contenu de la FIFO. Ajouter la pause entre l'envoi des caractère permet à la FIO d'être pleine moins souvent et donc permet de moins souvent solliciter le PC pour qu'il arrête ou reprenne l'envoi des données vers l'imprimante.
Question 3.3
Si l’on ne souhaitait pas optimiser la taille de la FIFO (pour des raisons de coût par exemple), on pourrait utiliser une FIFO d’au moins 3500 caractères, ainsi on serait sûr qu’elle serait assez grande pour stocker l’intégralité des caractères. Dans l’exercice, nous allons exploiter le fait que lorsque les derniers caractères seront reçus par l’imprimante, les premiers caractères auront déjà été imprimés et donc que la FIFO aura été partiellement vidée. Ainsi nous pourrons utiliser une FIFO plus petite que 3500 caractères.
En reprenant les données de l’exercice 3.1, nous avions

Recherchons  date à laquelle la réception des caractères par l’imprimante est finie ; nous savons qu’à ce moment là, elle a reçu
date à laquelle la réception des caractères par l’imprimante est finie ; nous savons qu’à ce moment là, elle a reçu  3500 caractères :
3500 caractères :  donc
donc 
Application Numérique:  s .
s .
La page est donc entièrement reçue au bout de 3,646 secondes. C’est à ce même moment que la FIFO est la plus remplie, car à partir de cet instant, la FIFO va pouvoir se vider au fûr et à mesure que l’imprimante va imprimer les caractères. La taille de la FIFO doit donc être égal à ce nombre de
caractères 
Application Numérique:  caractères.
Il faut donc une FIFO de taille minimale 2771 caractères pour pouvoir imprimer une page de 3500 caractères sans que l’imprimante doivent demander au PC d’arrêter l’envoi des données.
caractères.
Il faut donc une FIFO de taille minimale 2771 caractères pour pouvoir imprimer une page de 3500 caractères sans que l’imprimante doivent demander au PC d’arrêter l’envoi des données.
——————————————————————————————————–
4. Révision plateforme Ardiuno UNO
Lire le texte suivant qui est un rappel de ce qui a été présenté oralement pendant la première séance de TP:
Arduino est un plateforme de développement open-source qui se compose d'une carte microcontrôleur et d'un environnement de développement IDE associé. La carte Arduino UNO se compose de :
- un microcontrôleur 8-bit Atmega328p cadencé à 16Mhz (exécutant une instruction par cycle d'horloge)
- un convertisseur USB/UART TTL
- une régulation de tension 5v
- un connecteur au pas de 2.54mm au standard Arduino

L'environnement logiciel est composé d'un éditeur/compilateur (Arduino IDE) et d'un ensemble de librairies pour contrôler les différents périphériques de la carte. De nombreuses librairies sont également proposées par la communauté de développeurs. Le langage de développement est basé sur C++.
Le canevas d'un programme Arduino, se compose de deux fonctions principales à implémenter :
- void setup() : fonction d'initialisation appelée une fois au démarrage du microcontrôleur
- void loop() : fonction dont le corps est exécute en boucle (programme principal)
Les librairies exposent le plus souvent des classes permettant de voir les périphériques comme des objets manipulables au travers de leur méthodes. Par exemple l'interaction avec le port série de la carte se fait au travers de la classe Serial (classe statique) qui dispose des fonctions :
- void begin(int baud, MODE) : permettant d'initialiser le baudrate, la parité, le nombre de bits de stop
- char read() : permet de lire un octet depuis le port série
- void write(char c) : permet d'écrire un octet sur le port série
- int available() : permet de vérifier si un octet est disponible en lecture sur le port
- d'autres fonctions facilitant l'envoi et la réception de données (println)
L'utilisation des entrées/sorties numériques de la carte se fait au travers des fonctions:
- void pinMode(int pin, MODE) : configure la pin désignée en IN ou OUT
- int digitalRead(int pin) : renvoie la valeur binaire présente sur la pin désignée
- void digitalWrite(int pin, VALUE) : écrit la valeur LOW ou HIGH sur la pin designée
L'utilisation des entrées analogiques de la carte se fait au travers de la fonction:
- AnalogRead(int pin) : lit la valeur analogique présente sur la pin designée A0-5. La valeur retournée est entre 0-1023, un incrément de 1 correspondant à une valeur de 5/1024v soit 4.9mv.
D'autres classes (SPI, Wire) permettent d'interagir avec les bus SPI, I2C présents sur la carte.
5. Utilisation à bas niveau de la liaison série Hardware sur Arduino
Le processeur de l'arduino dispose de plusieurs périphériques USART intégrés. La librairie Arduino Serial permet d'utiliser un de ces périphériques en tant qu'UART à haut niveau (pas d'interaction avec les registres du processeur) mais il est possible d'utiliser ce périphérique en configurant “à la main” les registres du processeur.
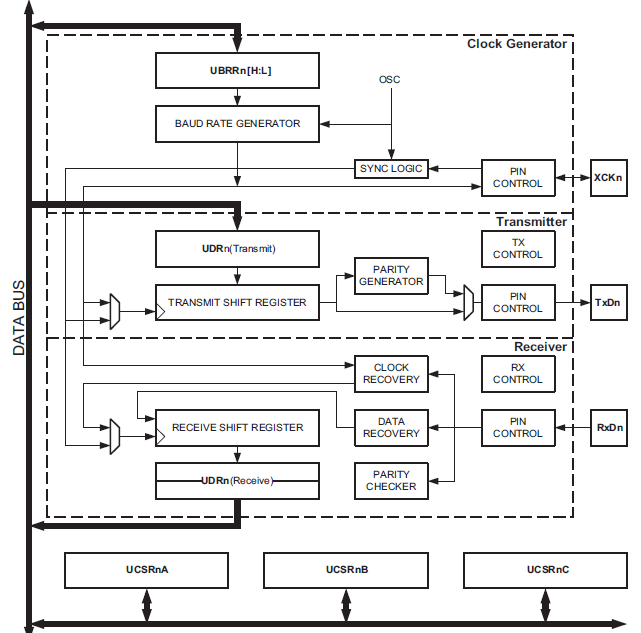
La figure suivante montre la vue interne de l'USART:
Question 5.1
Ouvrir dans un nouvel onglet la documentation du composant ATMEGA328P: https://ww1.microchip.com/downloads/en/DeviceDoc/Atmel-7810-Automotive-Microcontrollers-ATmega328P_Datasheet.pdf
Lire les pages 1 et 2 et faire le lien avec les informations données lors du premier TP.
Observer le schéma en page 6 et repérer le coeur de processeur ainsi que différents périphériques, notamment l'USART 0 intégré dont la documentation détaillée se trouve en page 143. Lire en détail la partie 19.1
Recopier le schéma de la page 144 et indiquer les éléments que vous reconnaissez. Pour vous aider à comprendre le schéma:
La lettre n est un indice indiquant qu'il y a plusieurs fois le même composant USART dans l'ATMEGA et qu'il faut remplacer n par le numéro de l'USART que l'on souhaite utiliser.
Les blocs UDRn sont en fait un même registre. La donnée écrite par le programme dans le registre se retrouve dans le bloc UDRn (Transmit) pour transmission sur le bus alors qu'une donnée reçue depuis le bus se retrouve dans UDRn (Receive) et peut être lue par le programme. UDRn ne se comporte donc pas comme un registre de mémoire: Une donnée écrite dans UDRn ne peut pas être relue par le programme.
Les blocs UCSRnA, UCSRnB et UCSRnC sont des registres de configurations et de contrôle dont les détails sont donnés à partir de la page 159.
Question 5.2: Configuration du baudrate
Le baudrate est configurable au travers du(es) registre(s) UBRR0 (UBRRn, n=0 pour l'USART 0) (voir tableau de baudrate en page 163 à 165).
La valeur à charger peut être établie par la formule: UBRRn = (fosc/16)/baudrate
1) Pourquoi l'utilisation d'un oscillateur principal à une fréquence fosc=16Mhz ne permet pas toujours d'obtenir un taux d'erreur de 0% ?
2) Proposer une fréquence d'oscillateur permettant un baudrate à 9600bds et un taux d'erreur de 0%
3) Dans le cas de l'utilisation d'un oscillateur à 16Mhz et d'un baudrate à 9600bauds, calculer la longueur de la séquence de bits avant qu'une erreur survienne (on considérera que l’échantillonnage du premier bit (le start) est réalisé au milieu de sa durée).
4) Déterminer la valeur à charger dans UBBRn pour fosc=16Mhz et un baudrate souhaité de 2400Bauds. Cette valeur tient elle sur 8bits?
Question 5.3: Configuration du format de la trame
Le registre USCRnC (USART Status and Control register C) permet de configurer le format de la trame UART (nombre de bits, parité, nombre de bits de stop).
1) Établir la configuration pour une communication 8N1 et proposer une séquence de configuration en langage C (indiquer les valeurs à charger dans les différents registres)
2) Établir la configuration pour une communication 8E2 et proposer une séquence de configuration en langage C (indiquer les valeurs à charger dans les différents registres)
Question 5.4: Envoi et réception de données
L'envoi de données sur la liaison UART se fait par l'écriture dans le registre UDRn. Avant d'effectuer l'envoi d'une donnée, il faut d'abord vérifier que l'UART et disponible pour l'émission (dernière donnée envoyée) à l'aide du registre UCSRnA. Pour recevoir des données, il faut tout d'abord vérifier qu'une donnée est disponible à l'aide du même registre
1) Proposer une séquence en langage C permettant d'émettre un caractère sur l'UART
2) Proposer une séquence en langage C permettant de recevoir un caractère sur l'UART
Solutions partie 5:
Question 5.1
Sur le schéma de la page 144, la partie supérieure “Clock Generator” sert au signal d'horloge. Comme le composant est un USART, il permet de communiquer de manière asynchrone ET synchrone. Dans cas asynchrone (a), le signal d'horloge est généré en interne sur chacun des hôtes et le signal n'est pas échangé à travers la broche XCKn. Dans le cas synchrone, il faut encore différentier deux cas: (s1) Soit le signal d'horloge est généré par l'USART et transmis vers l'hôte distant à travers la brôche XCKn configurée en sortie, (s2) soit le signal d'horloge est généré par l'hôte distant et arrive sur l'USART via la broche XCKn configurée en entrée. Dans les cas (a) et s(1), l'USART doit générer le signal d'horloge à partir de l'horloge du microcontrôleur, notée OSC sur le schéma, en le divisant par un facteur entier défini par le contenu du registre UBRRn (dont les lettres H et L font références à High et Low, parties poids fort et faible d'une valeur 16 bits rangée dans 2 registres 8 bits). Dans le cas (b), le signal d'horloge reçu sur la brôche XCKn est échantillonné temporellement grâce au bloc “Sync Logic” pour obtenir en interne un signal bien stable.
La partie du milieu du schéma, “Transmitter”, est utilisée pour générer le signal émis sur la brôche TxDn. A gauche, un multiplexeur est utilisé pour choisir parmi les 2 signaux d'horloges possibles (vu juste au dessus). Le registre UDRn sert à stocker temporairement la donnée en attente d’émission. Au moment opportun, cette donnée est chargée de manière parallèle dans le registre à décalage de transmission. Les bits de données de la trame sortant sous forme série de ce registre sont aiguillés via le multiplexeur à droite vers la brôche TxDn, mais servent également à mettre à jour la valeur du bit de parité à l'intérieur du bloc “Parity generator”, qui complémente sa propre sortie chaque fois qu'un bit en entrée est à 1 (il calcule dynamiquement le XOR entre tous les bits de données de la trame). Après les bits de données, si le contrôle de parité est activé, le multiplexeur aiguille sur la brôche TxDn la sortie du bloc “Parity generator” correspondant à la valeur du bit de parité de la trame.
La partie du bas du schéma, “Receiver”, est utilisée pour décoder le signal reçu sur la brôche RxDn. A gauche, un multiplexeur est utilisé pour choisir parmi les 2 signaux d'horloges possibles (vu juste au dessus). On peut noter une différence par rapport au bloc “Transmitter”, en effet, ici il faut pouvoir synchroniser le récepteur par exemple sur le front descendant du bit de start, et c'est le bloc “Clock Recovery” qui s'en charge. Le bloc “Data Recovery” permet quant à lui de lire la valeur des bits de données de la trame (en procédant à un sur-échantillonnage tel que visible sur la page 156 pour les plus curieux, afin de filtrer des parasites). Les bits de donnée ainsi reconstruits sont ensuite injectés en entrée série du registre à décalage “Receive Shift Register”, et lorsque tous les bits sont reçus, le contenu de ce registre est transféré de manière parallèle vers le registre UDRn pour lecture par le programme. Si le contrôle de parité est activé, le bloc “Parity checker” est utilisé pour vérifier la parité de la trame reçue et indiquer via un drapeau (bit d'un registre de contrôle de l'UART) si elle est correcte ou non.
Comme indiqué dans l'énoncé, les blocs UCSRnA, UCSRnB et UCSRnC sont des registres de configurations et de contrôle dont les détails sont donnés à partir de la page 159.
Question 5.2
1) Pour obtenir une erreur relative de 0% sur le baudrate, il faut que le Baudrate soit un sous multiple entier de la fréquence d'oscillateur divisée par 16. Par exemple sur la table 19-9, pour fosc=1.8432Mhz et Baudrate=2400, il existe un facteur  , qui est réalisable par le bloc “Clock Generator” vu à la question précédente. Dans la question, il est demandé d'utiliser un oscillateur à 16MHz, il faut donc regarder la table de la page 165. Sur cette table, on voit deux cas différents en fonction de U2Xn (il s'agit d'un bit permettant d'activer ou non un diviseur de fréquence par 2).
Seules les 3 dernières lignes de la table correspondent à des baudrates pour lesquels il existe un facteur entier permettant de diviser le signal à 16Mhz. On notera que la valeur à écrire dans UBRR est la valeur de rechargement d'un décompteur qui décompte en boucle jusqu'à 0 compris, avec donc un module UBRR+1. Ainsi, si U2Xn=0, pour un baudrate de 250KHz par exemple, il faut diviser 16Mhz par (16*4) et donc charger
, qui est réalisable par le bloc “Clock Generator” vu à la question précédente. Dans la question, il est demandé d'utiliser un oscillateur à 16MHz, il faut donc regarder la table de la page 165. Sur cette table, on voit deux cas différents en fonction de U2Xn (il s'agit d'un bit permettant d'activer ou non un diviseur de fréquence par 2).
Seules les 3 dernières lignes de la table correspondent à des baudrates pour lesquels il existe un facteur entier permettant de diviser le signal à 16Mhz. On notera que la valeur à écrire dans UBRR est la valeur de rechargement d'un décompteur qui décompte en boucle jusqu'à 0 compris, avec donc un module UBRR+1. Ainsi, si U2Xn=0, pour un baudrate de 250KHz par exemple, il faut diviser 16Mhz par (16*4) et donc charger  dans UBRRn. Dans la même situation, si l'on essaie avec un Baudrate de 9600Bauds, il faut charger UBRRn avec la valeur 103, et le Baudrate réellement obtenu est alors
dans UBRRn. Dans la même situation, si l'on essaie avec un Baudrate de 9600Bauds, il faut charger UBRRn avec la valeur 103, et le Baudrate réellement obtenu est alors  Bauds, ce qui conduit à une erreur relative de
Bauds, ce qui conduit à une erreur relative de  =0.16%
=0.16%
2) En cherchant dans les tables, on trouve par exemple en table 19-11, pour une fréquence fosc de 11.0592Mhz et un baudrate de 9600Bauds une erreur de 0%. En effet,  .
.
3) Ce calcul est théorique, et nous supposons ici que tout est parfait sauf le baudrate de l'USART utilisé. Nous avons calculé en 1) que le baudrate obtenu était erroné de 0.16%, donc l'erreur cumulée fera 50% de t_bit au bout de  bits, ce qui est largement plus grand que la plus grande trame utilisable avec cet UART, donc nous pouvons conclure qu'il n'y a pas de risque à utiliser ce baudrate légèrement erroné. Ce ne serait pas du tout le cas si nous avions voulu utiliser un baudrate de 230.4KBauds, car la table indique, pour U2Xn=0, une erreur relative de 8.5%, et donc nous aurions de problème dès le sixième bit de la trame. On pourra noter que la table nous invite alors à activer U2Xn afin d'abaisser l'erreur relative à 3.5% dans ce cas.
bits, ce qui est largement plus grand que la plus grande trame utilisable avec cet UART, donc nous pouvons conclure qu'il n'y a pas de risque à utiliser ce baudrate légèrement erroné. Ce ne serait pas du tout le cas si nous avions voulu utiliser un baudrate de 230.4KBauds, car la table indique, pour U2Xn=0, une erreur relative de 8.5%, et donc nous aurions de problème dès le sixième bit de la trame. On pourra noter que la table nous invite alors à activer U2Xn afin d'abaisser l'erreur relative à 3.5% dans ce cas.
4) La table 19-12 nous invite soit à charger:
- U2Xn=0 et UBRRn=416
- U2Xn=1 et UBRRn=832 (avec une erreur relative de baudrate plus faible)
Les 2 valeurs d'UBRRn ne sont pas codable sur 8bits, il faut donc charger le poids fort dans UBRRnH et le poids faible dans UBRRnL comme indiqué en 19.10.5 page 162.
Question 5.3
1) La page 161 présente en détail le contenu du registre UCSRnC.
Pour configurer l'interface en format de trame 8N1:
- Les bits UMSELn 1 et 0 doivent être mis à 0 pour fonctionner en mode asynchrone (UART).
- Les bits UPMn 1 et 0 doivent être mis à 0 pour désactiver le contrôle de parité.
- Le bit USBSn doit être mis à 0 pour avoir un seul bit de stop dans la trame.
- Les bits UCSZn 1 et 0 doivent être mis à 1 et 1 pour sélectionner une taille de mot de 8bits. (attention la documentation est piégeuse car la table 19.7 fait apparaître un bit UCSZn2 qui n'existe pas dans le registre UCSRnC, mais est à aller chercher dans le registre UCSRnB en page 160… Ce bit doit être mis à 0)
- Le bit UCPOLn n'a pas à être réglé car il concerne uniquement les modes synchrone
En récapitulant, il faut charger 0000 0110b=0x06 dans UCSRnC.
Dans UCSRnA, il faut veiller à régler le bit U2X0 pour activer ou inhiber le facteur 2 sur le baudrate.
Dans UCSRnB, il faut veiller à activer l’émission et la réception en positionnant les bits RXEN0 et TXEN0 à 1.
Dans la suite, nous écrivons du code pour configurer un UART particulier, en choisissant n=0 et en l'utilisant dans tous les noms de registres utilisés. Tout ceci peut être écrit à l'intérieur de la fonction setup(). Pour améliorer la lisibilité du code, on préférera utiliser des opérations | (ou logique), « (décalage) et les noms de bits correspondant à leurs numéros dans les registres plutôt que les valeurs constantes calculées précédemment:
- configuart.ino
void setup() { //Asynchronous Normal mode (U2Xn = 0) //unsigned int UBRR=16000000/(16*9600)-1; //103.16 //UBRR0H=UBRR/256; //UBRR0L=UBRR%256; UBRR0H=0; //poids fort du Baudrate divider UBRR0L=103; //poids faible du Baudrate divider UCSR0A = (0<<U2X0); //pas de double Baudrate UCSR0B=(1<<RXEN0) | (1<<TXEN0) ; //UCSZ02=0 pour 8 bits de données UCSR0C=(1<<UCSZ01) | (1<<UCSZ00) ; // Asynchronous USART, Parity Mode 00, 1 stop bit, 8 bits de données }
2) Pour configurer l'interface en format de trame 8E2:
- Les bits UMSELn 1 et 0 doivent être mis à 0 pour fonctionner en mode asynchrone (UART).
- Les bits UPMn 1 et 0 doivent être mis à 1 et 0 pour activer le contrôle de parité en mode Even (pair).
- Le bit USBSn doit être mis à 1 pour avoir deux bits de stop dans la trame.
- Les bits UCSZn 1 et 0 doivent être mis à 1 et 1 pour sélectionner une taille de mot de 8bits.
- Le bit UCPOLn n'a pas à être réglé car il concerne uniquement les modes synchrone
En récapitulant, par rapport à l'exercice précédent, il faut juste changer la valeur de chargement à 0010 1110b=0x2E dans UCSRnC.
Question 5.4
1 et 2) Il est possible de répondre à ces deux questions en lisant attentivement les descriptions des registres de la documentation et en réfléchissant un peu…. Ou bien le lecteur pourra regarder en pages 150 et 152 de la documentation le code fourni en C (attention à bien consulter les exemples pour des trames de 5 à 8 bits de données).
Le code suivant est un copié collé de la documentation auquel l'enseignant a ajouté des commentaires en français. Il conviendra dans le code de remplacer le numéro d'UART n par la bonne valeur:
- transmitreceive.ino
void USART_Transmit(unsigned char data) { /* Wait for empty transmit buffer */ while (!(UCSRnA & (1<<UDREn))); //Il s'agit d'une boucle d'attente bloquante qui ne fait rien tant que le bit UDREn du //registre UCSRnA n'est pas passé à 1. Ce bit passe à 1 lorsque la précédente donnée a //été transmise dans le registre à décalage et donc lorsque le registre UDRn est prêt à //recevoir une nouvelle donnée. Le bit UDREn repasse automatiquement à 0 lorsqu'une //nouvelle donnée est écrite dans le registre UDRn, ce qui est le cas à la ligne suivante. /* Put data into buffer, sends the data */ UDRn = data; } unsigned char USART_Receive(void) { /* Wait for data to be received */ while (!(UCSRnA & (1<<RXCn))); //Il s'agit d'une boucle d'attente bloquante qui ne fait rien tant que le bit RXCn du //registre UCSRnA n'est pas passé à 1. Ce bit passe à 1 lorsqu'une nouvelle donnée est //transférée depuis le registre à décalage vers le registre UDRn, indiquant au //programme qu'il y a une donnée à venir lire dans le registre UDRn. Le bit RXCn //repasse automatiquement à 0 lorsqu'une lecture est faite depuis le registre UDRn, //ce qui est le cas à la ligne suivante. /* Get and return received data from buffer */ return UDRn; }